How Critical Are Outliers in Transformer Models? A Live Experiment - Phase 1
Introduction
Many assume that large language models (LLMs, Transformers) simply “memorize data” due to their scale. In reality, some part of their "intelligence" and creative capacity is packed into outlier values, extremely large or small numbers in their weight matrices and activation tensors. In this post, we’ll zero out these outliers and directly observe how this disrupts the model’s output and behavior.
What is an Outlier?
An outlier is a value in a weight matrix or activation tensor that is much larger (or much smaller) than the typical values in that tensor.
- Formally, values where
|x| > thresholdare considered outliers for a given threshold. - In transformers, outliers are often the carriers of rare, complex, or contextual knowledge, the “atoms of intelligence.”
- Modern quantization literature (LLM.int8, GPTQ, AWQ, etc.) all stress that outliers are crucial for preserving model quality in large models.
Why Use PyTorch Hooks? How Did We Analyze Activations?
PyTorch forward hooks allow you to monitor internal activations of your model live during forward passes, without changing the model architecture. They’re the cleanest way to get detailed, layer-by-layer views of the model’s computation.
Example Hook Usage
activations = {}
def hook_fn(module, input, output):
# This function records the output (activation) of a module during forward
activations[module] = output.detach().cpu()
hooks = []
for name, module in model.named_modules():
if isinstance(module, (torch.nn.Linear, torch.nn.LayerNorm)):
hooks.append(module.register_forward_hook(hook_fn))
for name, module in model.named_modules():
if module.__class__.__name__ == "Gemma3RMSNorm":
hooks.append(module.register_forward_hook(hook_fn))
- Hooks are attached to every Linear and custom RMSNorm layer.
- During every forward pass, their output activations are stored in the
activationsdict. - This enables detailed layer-by-layer analysis: you can plot distributions, count outliers, and generate heatmaps of outlier presence across the network.
Hooks let us “see inside” the model as it thinks—crucial for understanding where and how outliers arise, and how they're normalized (or suppressed) across layers.
Outlier Suppression: What Did We Observe?
1. After a dummy forward pass (simple input),
- I closely inspected layers 0 and 1 and found many outliers (values exceeding our threshold, e.g., 2.0 or 5.0), especially in the outputs of early normalization layers.
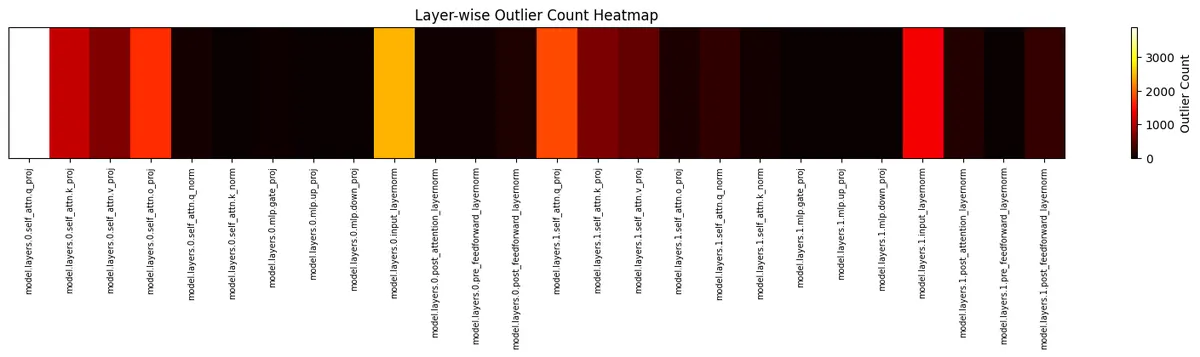
- When visualized as a heatmap or barplot, these outliers were heavily concentrated in the first 6-7 layers, then quickly “damped out” later layers 7-8 showed almost no outliers.
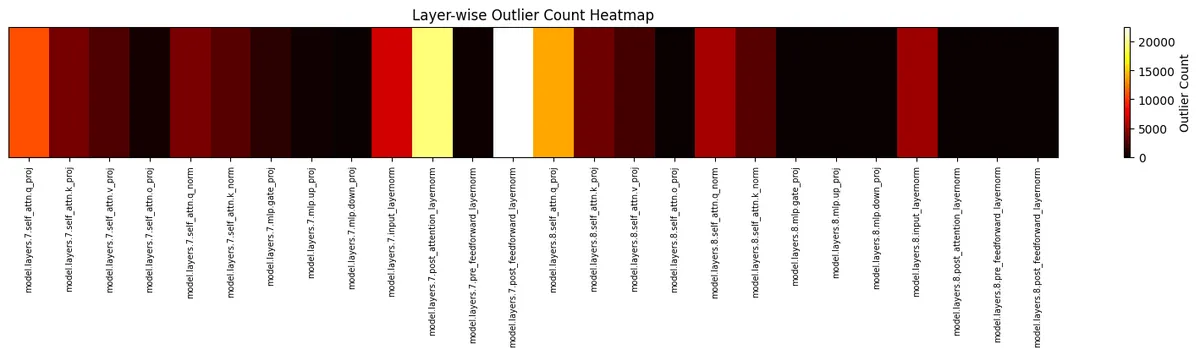
2. When I increased input length or complexity (for example, by repeating or lengthening the input sequence),
- Outlier activity extended further: outlier counts remained high up to deeper layers (e.g., up to layer 8, 9, or beyond) before being suppressed.
What does this mean?
- Early layers are much more sensitive to unusual, rare, or repeated input tokens—they “spike” with outlier activations as the model tries to encode novel or extreme information.
- As data flows deeper, normalization (LayerNorm, RMSNorm, etc.) and residual summing strongly suppress these outliers—keeping the representation stable, preventing numerical explosion.
- Longer or more extreme inputs push outlier activity deeper into the network, demonstrating how the model dynamically manages information flow based on input complexity.
Outlier Zeroing Function — Code & Explanation
def zero_outliers(module, threshold=5.0):
with torch.no_grad():
if hasattr(module, 'weight') and module.weight is not None:
mask = module.weight.abs() > threshold
module.weight[mask] = 0.0
if hasattr(module, 'bias') and module.bias is not None:
mask = module.bias.abs() > threshold
module.bias[mask] = 0.0
Why torch.no_grad()?
- Ensures parameter changes aren’t tracked in the computation graph (no autograd pollution or silent bugs).
- Clean, efficient, and prevents side effects, especially if you accidentally run this in training mode.
Why zero (0.0), not epsilon?
- Setting outliers to zero completely removes their influence so we want to measure maximum possible effect on the model’s behavior.
- Epsilon would leave a tiny signal, “masking” the real impact; 0.0 gives the clearest demonstration.
- If you only threshold (not all values!), full-tensor zeroing is rare and numerical errors (NaN, inf) are unlikely.
Experiment: What Happens to Output Quality?
1. Model and Tokenizer Setup
from transformers import AutoTokenizer, AutoModelForCausalLM
from copy import deepcopy
import torch
MODEL = "google/gemma-3b" # Or any model you can fit on your hardware
tokenizer = AutoTokenizer.from_pretrained(MODEL)
model = AutoModelForCausalLM.from_pretrained(MODEL, dtype=torch.float16, device_map="auto")
subject_model = deepcopy(model)
2. Zero Out Outliers
for name, module in subject_model.named_modules():
zero_outliers(module, threshold=5.0)
3. Run Inference
prompt = "Write me a article about love."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
torch.manual_seed(42)
with torch.no_grad():
orig_out = model.generate(**inputs, max_new_tokens=40)
subj_out = subject_model.generate(**inputs, max_new_tokens=40)
orig_text = tokenizer.decode(orig_out[0], skip_special_tokens=True)
subj_text = tokenizer.decode(subj_out[0], skip_special_tokens=True)
print("--- Original Model Output ---")
print(orig_text)
print("--- Outlier-Zeroed Model Output ---")
print(subj_text)
Results:
Original Model:
Write me a article about love. Love is,
In my heart, is the purest substance. I never feel the love
It surrounds me. For ever I am surrounded by love.
Subject Model:
Write me a article about love. Love is, 3, love is one of the hardest, most powerful words I’ve
ever heard. It’s like when you learn that you don’t know how
The original model responds with imaginative, varied, and poetic output. It “gets” the topic and expands on it naturally. The outlier-zeroed model outputs cliches, even random numbers ("3,"), incomplete or looping sentences, clear loss of creativity, contextual connection, and output quality.
Okay, this may not make sense. But hear me out:
Original Model:
<bos>How do I create an array in Python?
The following is my first attempt at creating an array.
This is a string which I would like to separate as an array. I have set up
Subject Model:
<bos>How do I create an array in Python?
How do I create an array in Python?
How do I create an array in Python?
How do I create an array in Python?
How
That's a hit!
Outlier Impact Scales With Model Size
- As models grow (6B, 8B, 13B, 70B+), outlier count and impact increases sharply. If you zero or ignore outliers in large models, output quality and “intelligence” collapses (LLM.int8, GPTQ, AWQ papers).
- Small models also show clear degradation, but effects are much more dramatic in bigger LLMs. You can observe this even on 270M–2.7B models on commodity hardware.
Hardware, Precision, and Real-World Limits
- On 8GB VRAM (I have RTX 3070 Ti), you can’t always fit large models, so I used small ones, the effect is still visible and meaningful.
- Don’t let hardware limit stop your analysis.
Conclusion
These simple experiments prove that outliers are not “statistical noise”, they are the backbone of creativity, context, and reasoning in LLMs. Outlier removal or mishandling devastates generation quality. Even on small models, the effect is observable; on large models, it is catastrophic.
With hooks and targeted visualization, you can see exactly where and how outliers are generated and suppressed in the network.
Even with limited hardware, you can demonstrate and understand the foundational importance of outliers—quantization and efficient inference must handle them carefully.
If you want more technical deep-dives or code help, reach out!